Python Web browser scraper with Scrapy: Your First Spider End-to-End.
A Scrapy web scraper is aPythonframework to extract structure data on websites with the help of spiders, items, pipelines, and settings. Newcomers are able to install Scrapy, set up a project, create a spider and extract data using CSS selectors in minutes and store the results in JSON or CSV.

Table of Contents
- What Is a Scrapy Web Scraper?
- Key Definitions
- What is my first spider?
- The Work of Items, Pipelines, and Settings.
- Exporting Data (Exporting Feeds)?
- Is Web Scraping legal in the USA?
- Scraping Checklist
- |human|>Scraping Checklist Responsible.
- Common Mistakes + Fixes
- Compared to Other Tools (Comparison Table), Scrapy is also the best.
- FAQ
- Summary
What Is a Scrapy Web Scraper?
Scrapy web scraper is a free Python library which is used to automate web scraping. it supports scaling requests, parsing, and cleaning of data as well as exporting.
It operates extensively in the USA in the fields of price monitoring, aggregation of job listing and market research.
Key Definitions
- Scrapy Python Web scraper and crawler framework.
- Spider: This is a class that determines page crawling and parsing.
- Name: Scraped data Structured container.
- Pipeline: Clean and scrape processes.
- Settings: Characteristics of a scraper.
- Feed Exports: Have an in-built system of data export (JSON, CSV, XML).
What is my first spider?
It involves installing Scrapy, creating a project, creating a spider and running it.
Install Scrapy
pip install scrapy
Start Project
scrapy startproject myproject
cd myproject
Create Spider
scrapy genspider quotes quotes.toscrape.com
Edit spiders/quotes.py:
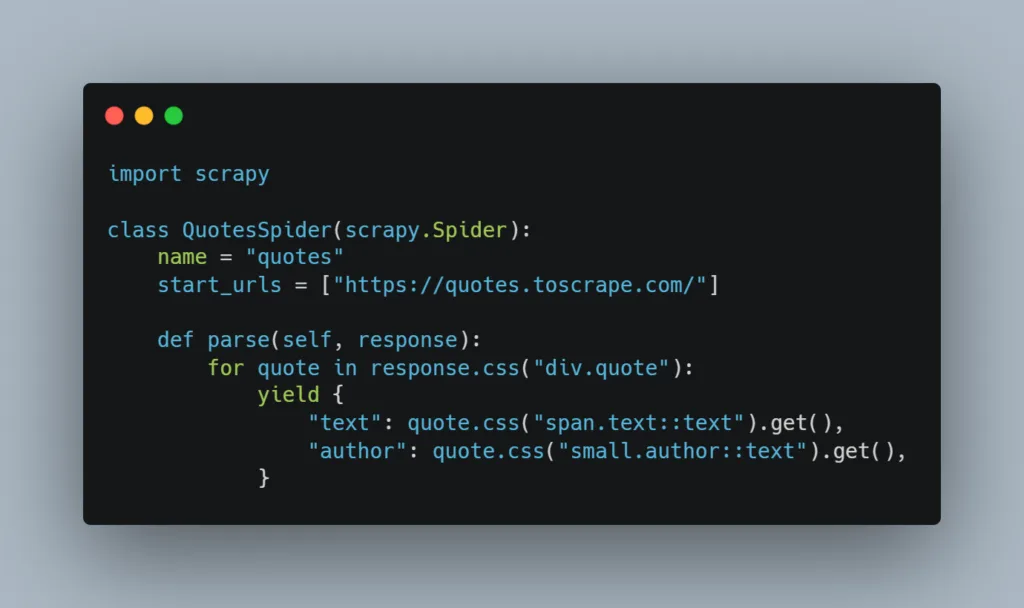
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = ["https://quotes.toscrape.com/"]
def parse(self, response):
for quote in response.css("div.quote"):
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("small.author::text").get(),
}
Run Spider
scrapy crawl quotes -o quotes.jsonThe Work of Items, Pipelines, and Settings.
Objects determine data formatting, pipelines handle information and configuration determines performance.
Item Example
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()Pipeline Example
class CleanTextPipeline:
def process_item(self, item, spider):
item["text"] = item["text"].strip()
return itemEnable in settings.py:
ITEM_PIPELINES = {
'myproject.pipelines.CleanTextPipeline': 300,
}Exporting Data (Exporting Feeds)?
Scrapy has command line support of JSON, CSV and XML.
scrapy crawl quotes -O quotes.csvOr in settings.py:
FEEDS = {
"quotes.json": {"format": "json"},
}Is Web Scraping legal in USA?
In most instances, web scraping is not illegal, although there is a limit. The Terms of Service and robots.txt file are always read by the scraper prior to scraping the site.
Do not scrape personal information, copywritten content or the use of authentication.
|human|>Scraping Checklist Responsible.
- Check robots.txt
- Respect rate limits
- Avoid personal/private data
- Follow Terms of Service
DOWNLOAD_DELAYis used in settings:
DOWNLOAD_DELAY = 2Common Mistakes + Fixes
| Mistake | Fix |
| Blocked IP | Add delay, turn user agents. |
| Visual inspector | Wizard CSS inspector |
| Slow down Too slow | Change concurrency settings |
| Broken JSON | Use -O instead of -o |
Scrapy vs Other Tools
| Weakness | Scrapy | BeautifulSoup | Selenium |
| Speed | High | Medium | Low |
| JS Support | Limited | No | Yes |
| Built-in Export | Yes | No | No |
| Recommended | Large crawls | Simple pages | JS-heavy sites |
FAQ
1. What is a Scrapy spider?
A spider is a type that spells out rules of crawling and logic of parsing.
2. What is the way to scrape multiple pages?
accompanied by response.follow() within a call to the method, which is the one being called, parse.
3. Is Scrapy able to work with JavaScript?
Not a native, use Splash or Selenium.
4. What is an item pipeline?
An element reconstructing scraped information.
5. How do I slow down scraping?
DOWNLOAD_DELAY settings Set DOWNLOAD_DELAY.
6. Can I export to CSV?
Yes, use -O file.csv.
7. Why am I getting 403 errors?
You might require headers or reduced rates of request.
8. Is Scrapy good for beginners?
Yes, it is well structured and documented.
Glossary
- Crawler: This is a program used to navigate websites.
- Selector: This is a tool used to scrape HTMLs.
- Concurrency Number of simultaneous requests.
Beginner Checklist
- Install Python
- Install Scrapy
- Create project
- Define spider
- Test selectors
- Export data responsibly
Summary
A Scrapy web scraper allows novices to construct scalable spiders with items, pipelines, settings and feed exports. Via large scale, organized project design and responsible scraper methods, you will be able to harvest clean and organized data in the USA in a legal and efficient manner.
Leave a Reply