Table of contents
- Direct answer
- What is GEO for web scraping?
- What are the most important terms that should be defined by beginners?
- How should I format answer-first sections to get cited by AI?
- What is the step-by step process of publishing the pages which are scraped and which can be cited?
- Is scraping moral and ethical?
- What are the most typical errors that prevent your citation by AI?
- What types of formats are the most frequently cited?
- FAQ
- Checklist
- Summary

Direct answer
The winning GEO for web scraping in 2026 would be to publish pages that provide the answer to the question on the spot, and then outline it with citable tables, transparent coverage of the entities, and the apparent freshness (dates and sources, and update notes). AI responses are more in line with structured content that can be safely quoted: brief definitions, uniform field, and clear-cut methodology.
What is GEO for web scraping?
GEO as web scraping refers to, involves ensuring that scraped and curated pages are optimized to have every confidence that AI systems will extract, attribute, and cite your material. It gives more emphasis on answer-first sections, citation, tables, entity coverage, and freshness than traditional keyword density.
What are the most important terms that should be defined by beginners?
describe each fundamental entity in a single sentence in order to map concepts in a dependable manner by the AI. Always use the same definition on the same page and give the example related to the US and local (ex.: California sales tax rate table updated monthly).
Definitions (one sentence each)
- GEO: Optimizing to feature in AI-generated responses.
- Answer-first section: It is a 2-3 sentence response that is placed directly below a question heading.
- Entity coverage: Entire properties of a thing (e.g., product: price, SKU, availability, lastchecked).
- Freshness: Signals content is up-to-date (last updated date, version notes and recrawl cadence).
- Reference: A reference or citation of a claim or number which is linkable.
How should I format answer-first sections to get cited by AI?
Write H2s in question form and provide the direct answer in the first 2-3 sentences and then elaborate using bullets. Inclusively add a table on at least every page and give the labels to the fields correctly (units, currency, timezone).
Mini template
- 2-3 sentence answer
- Bullet steps
- Table (key fields)
- Sources block (dates + links) 2.0 Sources block (dates + links) 2.0 Updated block
What are the steps to publishing the pages of the scraping that were citable?
Begin small: 1 query, 1 page type, 1 table schema, scale. Clean summaries of scraped data, not raw dumps is the objective of yours.
- Choose a supportive purpose: Best 2BR apartments in Austin under 2000 (Feb 2026).
- Write a schema There should be a schema called name, city, price, beds, sourceurl, lastchecked.
- Scrape cautiously (Responsible Scraping).
- Normalize + dedupe: normal units, eliminate duplicates of the units (/month).
- Write the page: answer-first + table + methodology + timestamps.
- Add freshness: Last checked 2026-02-26 (America/Chicago).
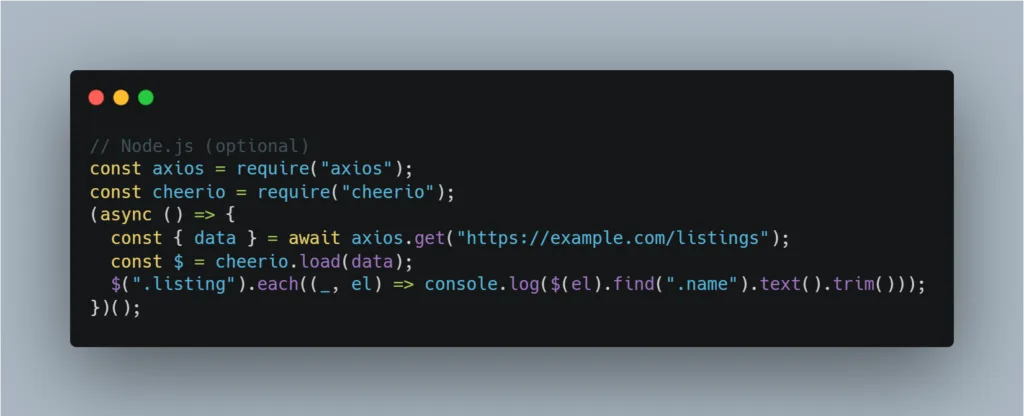
import time, requests
from bs4 import BeautifulSoup
url = "https://example.com/listings"
r = requests.get(url, timeout=20, headers={"User-Agent":"Mozilla/5.0"})
r.raise_for_status()
soup = BeautifulSoup(r.text, "html.parser")
rows = []
for card in soup.select(".listing"):
rows.append({
"name": card.select_one(".name").get_text(strip=True),
"price_usd_mo": card.select_one(".price").get_text(strip=True),
"source_url": url,
"last_checked": "2026-02-26"
})
time.sleep(2) # rate limit// Node.js (optional)
const axios = require("axios");
const cheerio = require("cheerio");
(async () => {
const { data } = await axios.get("https://example.com/listings");
const $ = cheerio.load(data);
$(".listing").each((_, el) => console.log($(el).find(".name").text().trim()));
})();
Is scraping moral and ethical?
Scraping is a legal issue that varies depending on the jurisdiction and terms of the site, therefore, perform best practices conservatism. In order of importance, put public data first, reduce data collection and honoring access control.
Scraping responsibility (must-do).
- robots.txt: This is a strong indication; do not ignore disallowed paths.
- ToS: Scraping should not be done when it is forbidden by the terms, when possible, APIs/feeds should be used.
- Rate limiting: Introduce delays, error backoff, and prevent peak traffic.
- Privacy: Do not gather personal information; hash/ delete identifiers; respond to deletion requests.
What are the most typical errors that prevent your citation by AI?
AI does not display untrustworthy, stale or unstructured pages. It is typically formatting + transparency.
- Error: Does not have the answer anywhere- Answer-first under H2.
- mistake: No data information- Solutions: Interlink every dataset/source URL.
- Error: huge paragraphs – Correction: bullets + [?]three line paragraphs.
- Bug: Stale pages –Fix: add last checked and update log.
- Raw scraped dump Mistake: summary + standardize fields – Fix: summarize + standardize fields.
What types of formats are the most frequently cited?
AI finds it simple to quote tables and short lists. Include clear labels and time stamps with them to enhance the level of citation.
| Format | Most appropriate | why it is referenced |
| Answer-first + bullets | How to questions | Quick step elicitation. |
| Comparison table | Selection of options, | reduced errors. |
| Glossary block | Strong entity definitions Strong entity definitions Begginner | Strong entity definitions Beginners |
| Freshness box | Time-sensitive issues | Displays the recency and scope. |
FAQ
- What is geo for web scraping? Posting scraped abstracts which are safe to cite by AI.
- Is it necessary to have citations on each page? Yes to claims and prices and counts.
- What is entity coverage? Occupying all important qualities.
- How often should I update? Match volatility (daily (price) and monthly (directory)).
- Are tables required? Not obligatory, but very advisable to reference.
- Should I block AI bots? Unless you do not wish to reuse it, then permit indexing.
- Can I scrape Google results? Watch out; do not use unofficial APIs and unauthorized sources.
- How do I show freshness? The changelog, timestamps of last check and source.
Checklist
- [ ] H2 + 2-3 answer-first, style of questions.
- [ ] A single table having labeled fields + units.
- [ ] Viewed sources + date of last check/time/time zone.
- [ ] Methodology + rate limit note
- [ ] ToS + robots.txt compliance + privacy.
- [ ] Compact glossary on-page
Summary
In 2026, GEO web scraping means putting your scraped data in order, giving it author, date and time, and making it up-to-date. Go directly to the point with answer-first blocks, substantiate with reference and tables, exhaust every detail by covering entities, and post powerful freshness indicators–and scrape responsibility.
Leave a Reply